Introduction to Delta Lake in Databricks
Disadvantages of Storing Data in Data Lake
- Historically, building a Cloud Data Lake with large amounts of data was a difficult system to build, as the Data Lake promised the following -
- Capturing as much data as possible
- Capturing data as quickly as possible
Despite of being sure that which data will actually prove to be valuable, the target of building a Data Lake was to pull in as much data as possible and as quickly as possible not knowing necessarily whether the data can be used or not.
2. In a Data Lake, like - Azure Data Lake Storage Gen 2 in Azure, where the underlying data of a Table is kept in the form of multiple files of any format, it becomes very difficult to perform the following operations on those files -
- Merge operation
- Updating a record, which may be present in any of those files
- Metadata Handling
- Version Controlling etc.
How Delta Lake Solves the Problem of Historical Data Lake?
- With the Delta Lake, it is possible to discover and analyze where to use the captured data to fit the needs of the organization.

Is It Necessary to Migrate Data from Other Databases to Delta Lake?
Since, Delta Lake is -
- Open-Sourced
- Leverages the Open-Sourced Data Formats
- Stores the data into the customer’s Cloud-Based Object Storage
- Definitely designed for infinite scalability
If the data from other Traditional Database Management Systems is chosen to be migrated to Delta Lake, it’s going to represent an investment in the long-term performance and viability of the data.
So, yes. Even if it takes a little bit of time to make the change, in the long run a significant increase in the long-term performance would be seen, as well as, an increase in the viability and usability of the data.
What is Delta Lake?
Delta Lake is an Open-Source Data Management Platform:
- Delta Lake is an Open-Source Project (delta.io). That means it is something that everyone has access to, through Open-Source Code.
- Delta Lake was actually developed exclusively by Databricks. But it’s open-sourced for more than 4 years now.
With Apache Spark, the Databricks is committed to working with the open-source community to continue to develop and expand the functionality of Delta Lake.
Delta Lake Leverages Standard Data Formats:
- Delta Lake is built upon standard data formats as Delta Lake is powered primarily by Parquet File Format.
Delta Lake can be considered as Parquet Format on steroid, because Delta Lake adds additional features that are not available in the standard Parquet File Format. This makes it so much easier to work with Big Data, i.e., huge amounts of data.
This additional Metadata leverages other Open-Source File Formats too, like — JSON.
Delta Lake is Optimized for Cloud Object Storage:
- Delta Lake can be run on a number of different storage mediums. It has been specifically Optimized though for the behaviour of Cloud-Based Object Storage, like — AWS, Azure and GCP.
It is known that the Cloud-Based Object Storage is cheap, durable, highly available and effectively infinitely scalable. There are plenty of rooms when it comes to Cloud-Based Object Storage. - It is possible to build Delta Lake on top of the data that is stored in the existing Cloud-Storage of any of the top three Cloud Services, like — S3 in AWS, Containers in Azure, and, GCP.
Delta Lake is Built for Scalable and Efficient Metadata Handling:
- The primary objective of designing the Delta Lake was to solve the problem of quickly returning queries in some of the world’s largest and rapidly changing dataset.
To return the result of any query in Delta Lake, the data is not needed to be locked into a Traditional Database Management System.
To store data in a Traditional Database Management System, there would be huge costs involved and scalability issues. As the data is Scaled Up, i.e., more data is added into a Traditional Database Management System, the cost is significantly increased.
- Delta Lake decouples the Storage Cost and the Compute Cost, and, provides optimized performance on the data, regardless of the scale.
Delta Lake Enhances Data Operations and Analytics:
- The Data Lakehouse is built upon the foundation of Data Lake and with the vision of powering applications that queries throughout the organization from a single copy of the data, i.e., One place for data which is used for different kinds of things — AI, ML, Data Engineering Pipelines etc.
What Challenges the Delta Lake Still Has?
- Although Delta Lake discovers and analyzes the captured data to take important business decisions of the organization, it is inevitable that there will be some unclean, or, inaccurate, or, totally useless data that have been captured into the Delta Lake.
- Having Garbage Data in the Delta Lake may not necessarily lead to a Cost Problem, because Cloud Storage is really inexpensive in the large scheme of things. Hence, it would not be that big of a deal to store data in Cloud Storage.
- But, the presence of the Garbage Data in the Delta Lake can be a huge Value Problem if the business decisions are made based on the data stored in the Delta Lake which are not trustworthy.
That’s why it needs to be made sure that it is possible to work through the captured data in the Delta Lake, make the data as valuable as possible, clean the data to not store the Garbage Data in the Delta Lake.

In What File Format the Data is Stored in a Delta Lake?
In a Data Lake, the data can be stored in any format, like - CSV, JSON etc.
- But, when any data is tried to be stored in a Delta Lake, it is stored in the form of a Delta Table.
- Although, the Delta Table is not actually a Table, but it is called so because, a Delta Table has all the features of a Relational Database Table.
- The underlying data of a Delta Table is stored in the Compressed Parquet File Format, i.e., in snappy. Parquet file format.
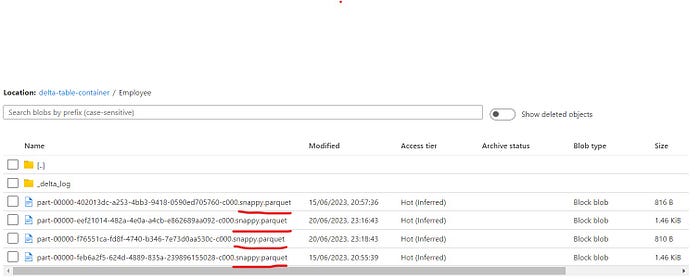
From Databricks Runtime 8.0 onwards, any Table that will be created in Databricks, will be a Delta Table by default.
Introduction to ACID Transaction
ACID properties are -
- Atomicity
- Consistency
- Isolation and
- Durability.
These are all properties of Database Transactions that are typically only found in Traditional Relational Database Management Systems or RDBMSs.
All of the ACID properties are available in the Delta Lake Architecture as well.
The ACID properties ensure -
- Data reliability
- Integrity
- Trustworthiness
The ACID properties prevent some of the issues that can be there with Data Contamination.
So, it needs to be made sure that there are Atomicity, Consistency, Isolation and Durability and that Transactions are used as different operations in the Delta Lake. So that, when the data is written, it is all going to be written into the Delta Lake, or the entire Transaction is failed.
Problems Solved by ACID Transaction
Following are five most common problems that the Data Engineers run into that can be solved by using the ACID properties -
Streamlined Data Append:
- Delta Lake - Delta Lake simplifies and improves data appending, making it efficient even with Concurrent Writes.
- ACID - There is guaranteed Consistency for State at the time the Append begins. Atomic Transactions and high Durability. The Appends will not fail due to the conflict even when writing from many sources simultaneously.
Simplified Data Modification:
- Delta Lake - Delta Lake simplifies data modification, ensuring Data Consistency.
- ACID - Upserts allow Updates and Deletes with simple syntax as a single Atomic Transaction.
Data Integrity through Job Failures:
- Delta Lake - Delta Lake prevents Data Inconsistencies due to Job Failures, maintaining Data Integrity.
- ACID - Changes are not committed until a Job has succeeded. Jobs will either completely fail or will completely succeed.
Support for Real-Time Operations:
- Delta Lake - Delta Lake serves as a robust Data Source, and, Sink for Real-Time and Streaming operations.
- ACID - Delta Lake allows Atomic Micro-Batch Transaction Processing. This is actually a Near-Real Time through tight integration with Structured Streaming.
Efficient Historical Data Version Management:
- Delta Lake - Delta Lake offers Time Travel for accessing historical data versions and its cost-effectiveness depends on the specific use-case and alternative solutions.
- ACID - The Transaction Logs are used to guarantee Atomicity, Consistency and Isolation, which allow to have Snapshot Queries. These Snapshot Queries allow to do things like - Time Travel, i.e., to look back and query Tables at previous moments in time, or, previous Versions of those Tables as well.
Key Features of Delta Lake
1. ACID Transaction - Although, a Delta Table is not a Relational Database Table, still Delta Lake introduces the concept of ACID Transactions on Spark.
2. Scalable Metadata Handling
3. Streaming and Batch Unification - A Delta Table in a Delta Lake can be a Batch Table, as well as, a Streaming Source and Sink.
4. Schema Enforcement - Delta Lake automatically handles the Schema variations of the data to be inserted into the Delta Tables to prevent the insertion of bad records.
5. Time Travel - Data Versioning in the Delta Lake enables the Rollbacks, and, Full Historical Audit Trail.
6. Upsert and Deletes - Delta Lake supports the Merge, Update, and, Delete operations to enable the complex use-cases, like -
- Change Data Capture (CDC)
- Slowly Changing Dimensions (SCD)
- Streaming Upsert, and, so on.
7. Data Skipping Index: Delta Lake employs File Statistics to Optimize the Query Performance by Skipping the unnecessary data scans.
So, if there are a handful of files, then Delta Lake is smart enough that it may not even scan some of those files based on the Optimization that is available directly in the Delta Lake. That saves time, which ultimately saves money.
Introduction to Medallion Architecture
For almost all Delta Lake use cases, the designs are framed in terms of Bronze, Silver and Gold Medallion Paradigm.
The source data may be coming from -
- Kafka
- CSV, JSON or TXT files
- Other Apache Spark source
Bronze Layer: The source data is brought, or, ingested into a Bronze level table, or a set of Bronze level tables. The Bronze level tables are just going to hold the raw data, i.e., totally uncleaned data.
The data in each of the Bronze level tables are exactly the same as when it arrived from the respective sources. This way there will always be something the Developers can fall back on. There will always be a copy of the source data.
- Especially when working with Kafka, which is Ephemeral, meaning that the Kafka data may be lost if the data is not pushed into a Storage Location that is going to save it.
Silver Layer : In the Silver level tables, the data present in the Bronze level tables are Filtered, Cleaned and Augmented with other data.
Gold Layer : In the Gold level tables, the data present in the Silver level tables are aggregated by mixing data from Silver level table with another, if needed. This creates the Business-Level Aggregates, which can then be used by BI Analysts, AI and ML folks and so forth.
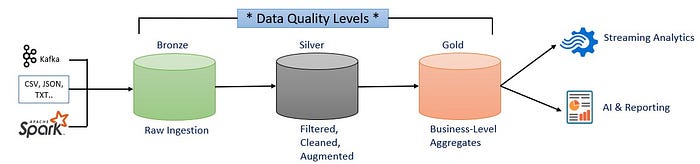
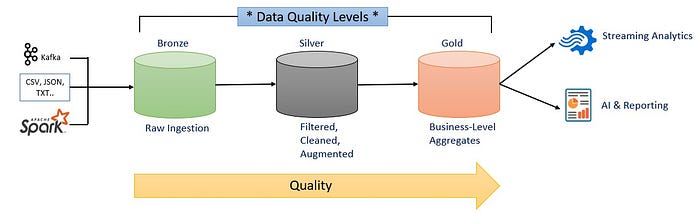
The Medallion Paradigm is available in lots of different ways of thinking as well.
The important thing is that the Quality of data in a Medallion Paradigm increases as the data is moved from Bronze to Gold.
Delta Lake allows to Incrementally improve the Quality of the data until it is Ready for Consumption by people within the organization.
How to Interact with Delta Lake in Databricks?
- It is possible to use Scala, Python, SQL or even R to work with Delta Lake in Databricks.
- Using SQL, the following query can be used to create a Delta Lake Table -
CREATE TABLE myTable
USING DELTA
Since, the default type of any table created in Databricks is Delta Lake Table, using the query USING DELTA is not necessary. Just using the query CREATE TABLE is going to create a Delta Lake Table only.

- Similarly using Python, the following syntax can be used to create a Delta Lake Table -
df.write
.format(“delta”)
Since, the default type of any table created in Databricks is Delta Lake Table, it is not necessary to pass delta to the format (), i.e., use the syntax format(“delta”). Just using the syntax df.write is going to create a Delta Lake Table only.

Data Objects in Databricks
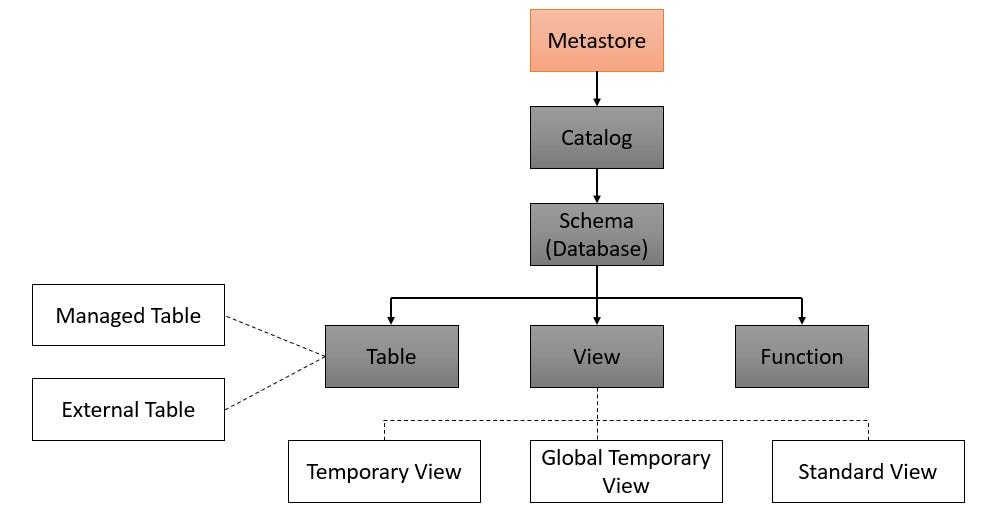
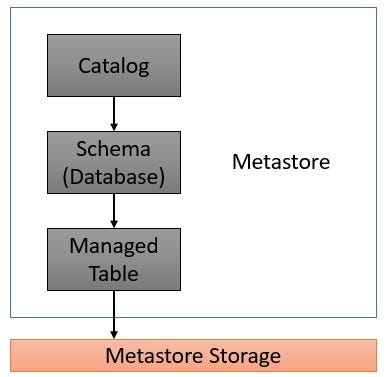
- Metastore: The top level data object is Metastore.
The Metastore can be thought of as the Root Location where the all other data objects, i.e., the Catalogs, Schemas, Tables, Views and the Functions are stored.
A Metastore is created by a Databricks Administrator, and, then a Databricks Workspace is assigned to each created Metastore. So, when the Developers work in a specific Databricks Workspace, that specific Databricks Workspace is going to have a specific Metastore configured. When the Developers work in a different Databricks Workspace, they might be working on a different Metastore, depending on how the Databricks Administrator has configured it for the Developers.
2. Catalog: Catalogs are really a grouping of Databases, or, Schemas.
Catalog is a means of hierarchically organizing the lower level data objects.
Example: there may be a Catalog, called accounting. There might be multiple Schemas within that accounting Catalog, each for specific needs of each accounting departments.
3. Schema (Database): Schemas can be logically thought of as Databases. Since, Databricks is not a Traditional Relational Database Management System, it is better to use the word Schema, but it is the same logical entity as a Database in any Traditional Relational Database Management System.
Every Catalog might have one or more Schemas within it, which is a means of organizing the data objects.
4. Tables: There can be one, or, multiple Tables inside a Schema. In Databricks, there can be two types of Tables -
- Managed Table: When a Databricks Administrator creates a Metastore, that Metastore is going to have a default Storage Location for data that is going to be written into it.
When a Managed Table is created, the Developers would be writing files, or, copying data files into a specific location, like a path, in the default Storage Location of the Metastore, which was configured when the Metastore was created. The path can be like a S3 Bucket in AWS, a Container in Azure etc.
When a Managed Table is dropped, the data of that table is going to be deleted from the specific location of the Metastore.
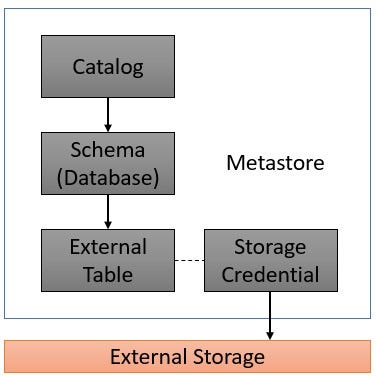
- External Table: If there is an External Storage Location, like an S3 Bucket in AWS, or, a Container in Azure that has a specific path where the existing data resides, then there would be a Storage Credential configured for accessing that specific External Storage Location.
When an External Table is created, the Developers would specify the specific path in an External Storage Location where the underlying data for that External Table currently exists.
Databricks checks if the Developers have access to the specified path in that External Storage Location through the Storage Credential.
If the Developers have access, then they would be able to query the data within the path.
5. Views: A View is really just a saved query that is typically run against one, or, more Tables, or, Data Sources.
Every time, a View is run, it re-queries the underlying Tables as well.
There are mainly the following kinds of Views in Databricks -
- Temporary View
- Global Temporary View
- Apart from these two types of Views, there is another kind of View, called the Standard View.
6. Function: A Function is just a saved logic that returns either a Scalar Value, or a Set of Rows.
A Function is saved within a Schema and can be used even when the Spark Session changes, or, when a Cluster is restarted.
Difference Between Managed and External Table
When working with both the Managed Tables and the External Tables, in terms of how the Developers work with the data present in those tables are the same.
The SELECT queries, the INSERT queries, all the works that the Developers would do with the data present in both the Managed Tables and the External Tables are transparent and looks the same.
- The difference between the Managed Tables and the External Tables lie in how the underlying Storage is configured.
- Managed Table: The underlying Storage of a Managed Table would be a path in the default Storage Location of the Metastore, which was configured when the Metastore was created by a Databricks Administrator.
- External Table: The underlying Storage of an External Table would be a path in an External Storage Location where the data for that External Table currently exists.
Introduction to Liquid Clustering
One of the most challenging aspects of working with the data is striving to Optimize the Reads and Write to save Time and Compute as much as possible, because, Time equals money as every time the Compute is used, it costs money.
Historically, Partitioning and Z-order have been used to Optimize the data objects. Databricks recently introduced a new technique to Optimize the data objects, i.e., Liquid Clustering.
- Liquid Clustering simplifies data layout decisions, and reduces maintenance burdens as well.
- When Liquid Clustering is used, the Developers no longer need to worry about the following -
- Optimal File Sizes of a Delta Table
- Partitioning a Delta Table
- Order of Partition Columns of a Delta Table
- The Frequency at which the Optimized Commands are chosen to run, etc.
Following are the features provided by Liquid Clustering -
- Fast: Liquid Clustering provides faster Writes and similar Read times compared to properly-tuned, or, well-tuned Partitioned Delta Tables.
- Self-Tuning: Liquid Clustering makes any Delta Table a Self-Tuned Delta Table, which means that the Developers do not need to worry about Over-Partitioning, or, Under-Partitioning a Delta Table.
- Incremental: Liquid Clustering automatically Clusters new data coming to a Delta Table.
- Skew-Resistant: Liquid Clustering provides consistent file sizes, and, low write amplification.
- Flexible: It is also possible to change the columns chosen to Cluster the data any time using Liquid Clustering. So, if a particular column is chosen to Cluster the data, and, in future, if a different column, or, a set of different columns need to be used to Cluster the data, it is possible to change easily and Liquid Clustering will take care of the rest.
- Better Concurrency: Liquid Clustering makes it easier for the works to be distributed amongst all the Nodes in the Compute for better Concurrency.
Scenarios that Benefit from Liquid Clustering
- Following are the scenarios that benefit from using Liquid Clustering -
- If the Delta Tables are often filtered by High Cardinality Columns
- If there is significant Skew in the data distribution of the Delta Tables
- If the Delta Tables grow rapidly and need maintenance and tuning all the time
- If the Delta Tables need Concurrent Write requirements
- If the Access Patterns of the Delta Tables change over time
- If there is a typical Partition Key that could leave the Delta Tables with too many, or, too few Partitions
Introduction to Deletion Vectors
- In the past, changing the existing data in a Delta Table would require Full Re-write of the required underlying files.
- With the use of the Deletion Vectors, the records to be Deleted, Updated and Merged in a Delta Table are written to a single file, called the Deletion Vector File. So that, all the required underlying files that need to be Fully Re-written are not getting Re-written at that time.
The Deletion Vector File keeps track of the changes made to a Delta Table, which saves Processing Time in the Compute.
At some point down the line, the required underlying files, for the DELETE, UPDATE and MERGE operations, are going to be Re-written when there is extra time, like at the time of running the VACUUM command. This is how the Deletion Vectors works. - Photon leverages Deletion Vectors for Predictive I/O Updates, i.e., it makes the DELETE, UPDATE and MERGE operations much faster. So that, it is not required to constantly wait for the Full Re-writes of the required underlying files to happen any time a DELETE, UPDATE or MERGE operation occurs.
Introduction to Predictive IO
- Predictive IO does the following things in Delta Lake -
- It automates the OPTIMIZE and VACUUM operations.
Previously, the OPTIMIZE and VACUUM operations needed to be run at a specific time manually. But now, Predictive IO uses Databrick’s years of experiences in building large AI, or, ML systems and then allow to predict when the OPTIMIZE and VACUUM operations need to be implemented, or, run. - It makes the Lakehouse a smarter Data Warehouse.
- It works to have the best cost, or, benefit available.
- It uses ML to determine the best way to provide the access to work with the data.
- It leverages Deletion Vectors to accelerate the speed of the DELETE, UPDATE and MERGE operations by effectively reducing the frequency of the Full Re-writes of the required underlying files of the Delta Tables.

