Nov 18, 2024
28 stories
3 saves
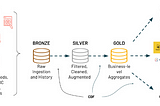
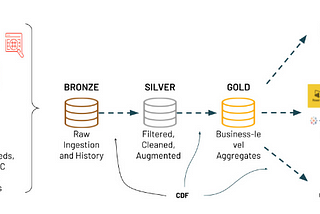
May 7, 2024
Table of Contents:
1. What is “Slowly Changing Dimension”?
2. “Different Methods” of “Handling” the “Slowly Changing Dimension”
i) SCD Type 1
ii) SCD Type 2
iii) SCD Type 3
3. What is “Merge”, or, “Upsert” Operation?
4. “Challenges” of Using “Merge” Operation in “Data Lake”
5. Did the Usage of “Delta Lake” Actually Solved the Problem of “Performing” the “Merge” Operation?
6. “Disadvantage” of Using “Spark SQL” to “Perform” the “Merge” Operation
7. Why It is Necessary for the “Developers” to Know the Usage of “Merge” Operation in “PySpark”?
8. “Create” the “Target Delta Table”
i) Create the Database “training”
ii) Create an “Empty Delta Table”
iii) “Display” the “Content” of the “Delta Table” (Currently “Empty”)
9. “Perform” the “Merge” Operation Using “Spark SQL”
A) First Load
I) Step 1: “Create” the “Source” for the “First Load”
II) Step 2: “Perform” the “Merge” Operation
B) Second Load
I) Step 1: “Create” the “Source” for the “Second Load”
II) Step 2: “Perform” the “Merge” Operation
10. “Perform” the “Merge” Operation Using “PySpark”
A) Third Load
I) Step 1: “Create” a “Delta Table Instance” Using “DeltaTableBuilder API”
i) What is a “Delta Table Instance”?
ii) What is the “Usage” of the “Delta Table Instance”?
iii) How to “Convert” the “Delta Table Instance” to “DataFrame”?
II) Step 2: “Create” the “Source” for the “Third Load”
III) Step 3: “Perform” the “Merge” Operation
B) Fourth Load
I) Step 1: “Create” a “Delta Table Instance” Using “DeltaTableBuilder API”
II) Step 2: “Create” the “Source” for the “Fourth Load”
III) Step 3: “Perform” the “Merge” Operation
Table of Contents:
1. What is “Join Selection Strategy”?
2. Why Learning About “Join Selection Strategies” is Important?
3. In Which Phase the “Join Selection Strategy” is “Selected”?
4. How “Many Types” of “Join Selection Strategies” are There in the “Apache Spark”?
5. How “Apache Spark” Decides Which “Join Selection Strategy” to “Choose”?
6. Dataset Used
7.
A) Sort Merge Join
I) Steps -
i) Phase 1: “Shuffle”
ii) Phase 2: “Sort”
iii) Phase 3: “Merge”
II) For What “Type” of “Join” the “Sort Merge Join” can be Used as the “Join Selection Strategy”?
III) How to “Disable” the “Sort Merge Join” as the “Default Join Selection Strategy”?
B) Shuffle Hash Join
I) Steps -
i) Phase 1: “Shuffle”
ii) Phase 2: “Hash Table Creation”
iii) Phase 3: “Hash Join”
II) Why the “Shuffle Hash Join” is “Termed” as “Expensive Operation”?
III) When the “Shuffle Hash Join” Can “Work” as the “Join Selection Strategy”?
IV) For What “Type” of “Join” the “Shuffle Hash Join” can be Used as the “Join Selection Strategy”?
C) Broadcast Hash Join
I) “Default Size” of the “Broadcast Threshold Limit”
II) Can the “Default Size” of the “Broadcast Threshold Limit” be “Changed” to “Any Other Value”?
III) How to “Disable” the “Broadcast Threshold Limit”?
IV) Why “Lesser Shuffling” Occurs in a “Broadcast Hash Join”?
V) What Happens When Both of the “DataFrames” in a “Join” are “Larger” Than the “Broadcast Threshold Limit” and “Broadcast Hash Join” is Used?
VI) How to “Explicitly Define” the “Broadcast Hash Join” as the “Join Selection Stratey” During the “Join” Operation?
Table of Contents:
1. Why “Broadcast Variable” is Used?
2. What is a “Broadcast Variable”?
3. When the “Usage” of the “Broadcast Variable” is “Most Suitable”?
4. What “Type” of a “Table” can be “Sent” Using the “Broadcast Variable”?
5. Can a “Large Table” be “Sent” Using the “Broadcast Variable”?
6. Can the “Size” of the “Table” that is “Sent” Using the “Broadcast Variable” be “Larger” than the “Size” of the “Memory” of the “Driver Node”?
7. “Internal Spark Architecture” of a “Normal Parallel Processing”
8. “Downside” of a “Normal Parallel Processing”
9. “Internal Spark Architecture” of a “Parallel Processing” With “Broadcast Variable”
10. Does the “Data” Sent Through “Broadcast Variable” Gets “Cached” in the “Worker Nodes” of a “Cluster”?
11. How Using “Broadcast Variable” in “Joins” “Improves” the “Performance”?
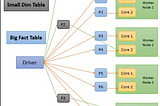
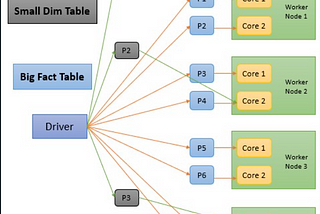
Table of Contents:
1. What is the “Importance” of “Partition”?
2. Why “Partition Strategy” is Needed?
A) “Choosing” the “Right Number” of “Partitions”
B) “Choosing” the “Right Size” of “Partition”
3. How to “Choose” the “Right Number” of “Partitions”?
4. How the “Unevenly Distributed Partitions” Actually “Decrease” the “Performance” of a “Spark Application”?
5. The “Default Number of Partitions” of “Data” that is “Generated” in the “Spark Environment”
6. The “Default Number” and “Default Size” of “Partitions” of “Data” that is “Read” from the “External Storage”
7. Can the “Default Number of Partitions” of “Data” that is “Read” from the “External Storage” be Changed?
8. For Which Type of “Files” that is “Read” from the “External Storage”, the “Default Number of Partitions” of “Data” can “Not” be “Applicable”?
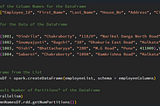
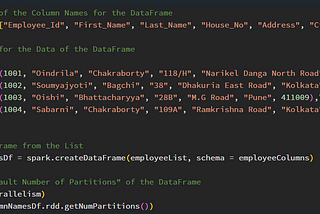
Table of Contents:
1. How “Delta Tables” Become “Slow” to “Query”?
2. How to “Speed Up” the “Query Performance” of the “Delta Tables”?
3. “Keep” the “Delta Tables” “Clean” Using the “VACCUM” Command
A) Important Aspect of “VACCUM” Command
B) Things to Remember When “Copying” the “Data Files” of a “Delta Table”
C) How to “Disable” the “Default Retention Interval”?
D) When the “VACCUM” Command is Used?
4. “Keep” the “Delta Tables” “Clean” Using the “OPTIMIZE” Command
A) How to “Change” the “File Size” of the “Table” on Which the “OPTIMIZE” Command is “Run”?
B) When the “OPTIMIZE” Command is Used?
C) “Drawbacks” of the “OPTIMIZE” Command
5. “Keep” the “Delta Tables” “Clean” Using the “Z-ORDER OPTIMIZE” Command
A) “Difference” Between “OPTIMIZE” and “OPTIMIZE Z-ORDER BY” Command
B) “Drawbacks” of the “OPTIMIZE ZORDER BY” Command
6. “Keep” the “Delta Tables” “Clean” Using the “Partitioning”
7. Use “ZORDER” and “Partitioning” Together
Table of Contents:
1. What is “Unity Catalog”?
2. Why “Unity Catalog” is Used “Primarily”?
3. In “What Type” of “Databricks Workspace”, the “Unity Catalog” can be Used?
4. Why “Unity Catalog” is Considered as “Unified Catalog”?
5. What is the “Data Lineage” Feature in “Unity Catalog”?
6. What is the “Data Sharing” Feature in “Unity Catalog”?
7. What is a “Hive Metastore”?
8. Can “Hive Metastore” of “One Databricks Workspace” be “Shared” with “Another Databricks Workspace”?
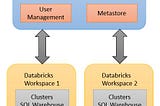
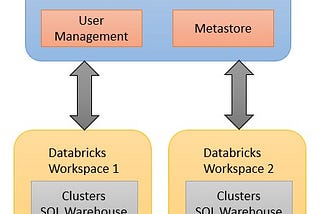
9. “Architecture” of “Unity Catalog”
A) Metastore
B) User Management
10. Unity Catalog Object Model
11. Who Can “Set Up” the “Unity Catalog” in “Databricks”?
12. Why the “Access Connector for Azure Databricks” Service is “Required” to “Set Up” the “Unity Catalog”?
13. “Steps” to “Enable” the “Unity Catalog” in “Databricks”
14. Important Features of “Unity Catalog”
Aug 14, 2023
Table of Contents:
1. “Disadvantages” of “Storing Data” in “Data Lake”
2. What is “Delta Lake”?
3. In What “File Format” the “Data” is “Stored” in a “Delta Lake”?
4. “Features” of “Delta Lake”
5. “Create” a “Delta Table”
A) “Create” an “External Delta Table”
i) “Create” an “External Delta Table” Without a “Name”
ii) “Create” an “External Delta Table” With a “Name”
B) “Create” a “Managed Delta Table”
6. “Query” a “Delta Table”
7. “Drop” a “Delta Table”
A) “Drop” an “External Delta Table”
B) “Drop” a “Managed Delta Table”
Table of Contents:
1. What is “Incremental ETL”
2. Features of “Incremental ETL”
A) Scalable
B) Idempotent
C) Complicated
3. Features of “Incremental ETL” in Databricks
4. Benefits of “COPY INTO” Command in “Incremental ETL” in Databricks
A) No Custom Bookkeeping
B) Accessible
C) Scalable
5. Usage of “COPY INTO” Command in “Incremental ETL” in Databricks
A) Destination
B) Source
C) File Format
6. Benefits of “AutoLoader” in “Incremental ETL” in Databricks
A) Easy to Use
7. “New File Detection Mode” of “AutoLoader” in “Incremental ETL” in Databricks
A) Directory Listing Mode
B) File Notification Mode
8. Data Ingestion Challenges Solved by “AutoLoader” in “Incremental ETL” in Databricks
9. How “AutoLoader” Helps in “Incremental ETL” in Databricks
A) Identify Schema on Stream Initialization
B) Auto-Detect Changes and Evolve Schema to Capture New Fields
C) Add Type Hints for Enforcement When Schema is Known
D) Rescue Data That Does Not Meet Expectation
10. Usage of “AutoLoader” in “Incremental ETL” in Databricks
A) Streaming Loads with AutoLoader
B) Batch Loads with AutoLoader
11. Check Point Location of “AutoLoader” in “Incremental ETL” in Databricks


Oct 25, 2022
Table of Contents:
1. What is “Execution Plan”?
2. Different Sections of “Logical Plans”
A) Parsed Logical Plan (Unresolved Logical Plan)
B) Analyzed Logical Plan (Resolved Logical Plan)
C) Optimized Logical Plan
3. What is “Physical Plan”?
4. What is “Catalyst Optimizer”?
5. How “Catalyst Optimizer” “Optimizes” “Queries”?
A) User Input
B) Unresolved Logical Plan
C) Analysis
D) Logical Optimization
E) Physical Planning
F) Cost Model
G) Whole Stage Code Generation
6. Limitation of “Catalyst Optimizer”


Table of Contents:
1. Limitation of External User-Defined Functions (UDF)
2. Benefits of Using SQL User-Defined Functions (SQL UDF)
3. Create SQL User-Defined Functions (SQL UDF) as Constants
4. Create SQL User-Defined Functions (SQL UDF) Encapsulating Expressions
5. Create Nested SQL User-Defined Functions (SQL UDF) Encapsulating Expressions
6. Create SQL User-Defined Functions (SQL UDF) Reading from Tables
7. Create SQL Table User-Defined Functions (SQL UDF)
8. Administering SQL User-Defined Functions (SQL UDF)
9. Future Extension to SQL User-Defined Functions (SQL UDF)


Table of Contents:
1. Handling Bad Records Using the following “Parsing Modes” -
A) PERMISSIVE (Default)
B) DROPMALFORMED
C) FAILFAST


Table of Contents:
1. What is “badRecordsPath” Option
2. Limitation of “badRecordsPath” Option
3. Example of “badRecordsPath” Option for Bad File (Missing File)
4. Example of “badRecordsPath” Option for Bad Records


