Nov 18, 2024
3 stories
1 save
Table of Contents:
1. What is Shuffle?
2. Why Data Needs to be Shuffled at All?
3. Significance of Shuffle
4. What is Shuffling Parameter?
5. How to Decide the Value of the Shuffling Parameter?
6. What are the Factors to Consider While Choosing the Value of the Shuffling Parameter?
7. How to Identify If Shuffle Has Occurred?
8. What is Shuffle Read and Shuffle Write?
9. How Shuffle Can be Reduced?
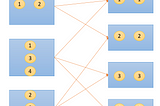
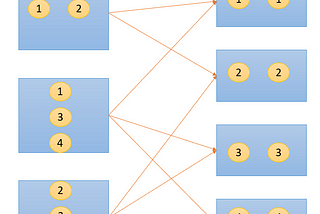
Table of Contents:
1. How the Size of Each Partition, of the Data to Process, is Estimated Initially in a Spark Application?
2. What is Skewness?
3. Does Data Skewness Occur Only When Partitioning a Dataset?
4. How to Identify Data Skewness in a Spark Application?
5. Data Skew Code
6. How to Solve the Data Skewness in a Spark Application?
i) Using Skew Hint
ii) Using Adaptive Query Execution (AQE)
Table of Contents:
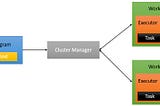
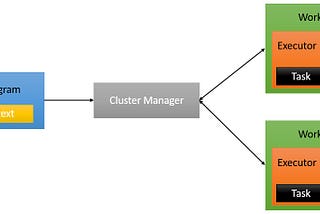
1. Recap of Parallel Processing Concept in Apache Spark
2. Recap of Spark Architecture
3. Recap of Internal Optimization Steps by Apache Spark
4. Levels of Optimization or Performance Tuning in Databricks
5. Five Most Common Performance Issues of an Application in Databricks
i) Skew
ii) Spill
iii) Storage
iv) Shuffle
v) Serialization
6. How One Performance Issue Can Cause Another Performance Issue?
i) Skew Can Induce Spill
ii) Storage Issues Can Induce Excess Shuffle
iii) Incorrectly Addressed Shuffle Can Lead to Skew